
太原中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2017-11-16 来源:黑马程序员 浏览量:
接下来我们要讲解爬取一些较难的数据评论:
1. 在Item中定义自己要抓取的数据:
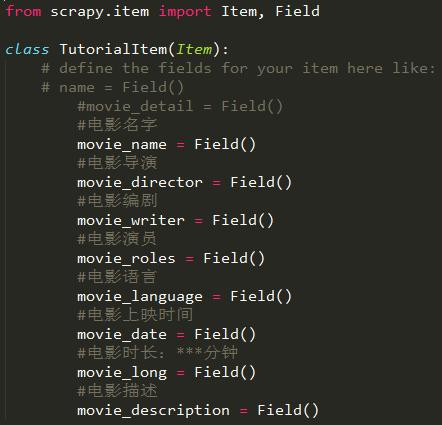
movie_name就像是字典中的“键”,爬到的数据就像似字典中的“值”。在继承了BaseSpider的类中会用到:
第一行就是上面那个图中的TutorialItem这个类,红框圈出来的就是上图中的movie_name中。
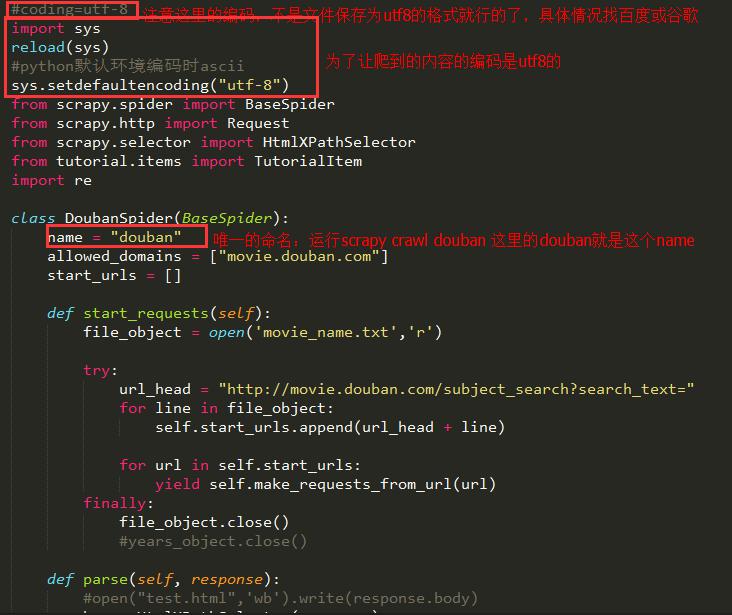
2、然后在spiders目录下编辑Spider.py那个文件
跟着上面的item是匹配的
3.编辑pipelines.py文件,可以通过它将保存在TutorialItem中的内容写入到数据库或者文件中。
对json模块的方法的注释:dump和dumps(从Python生成JSON),load和loads(解析JSON成Python的数据类型);dump和dumps的唯一区别是dump会生成一个类文件对象,dumps会生成字符串,同理load和loads分别解析类文件对象和字符串格式的JSON
4. 上述三个过程后就可以爬虫了,仅需上述三个过程哟,然后在dos中将目录切换到tutorial下输入scrapy crawl douban就可以爬啦
接下来就简单介绍下一些基本知识
5. start_requests方法:
直接在start_urls中存入我们要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写这个方法了,可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request。
那么这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入我们自定义的规律的链接。
6. parse方法:
生成了请求后,scrapy会帮我们处理Request请求,然后获得请求的url的网站的响应response,parse就可以用来处理response的内容。在我们继承的类中重写parse方法,parse_item是我们自定义的方法,用来处理新连接的request后获得的response。友情提示:获得更多学科学习视频+资料+源码,请加QQ:3276250747。
7. 在这个函数体中,根据 start_requests (默认为GET请求)返的 Response,得到了一个 名字为‘item_urls’ 的url集合。然后遍历并请求这些集合。再看 Request 源码

本文版权归黑马程序员人工智能+Python学院所有,欢迎转载,转载请注明作者出处。谢谢!
作者:黑马程序员工智能+Python培训学院




















.jpg)